Lineaire regressie
Machine learning is het wetenschappelijke gebied dat algoritmen bestudeert die kunnen leren van data. Het leren van data heeft over het algemeen twee doelen: het voorspellen van het volgende stukje informatie of het classificeren van een stuk informatie. Het voorspellen van informatie is moeilijk en wordt in de praktijk niet veel toegepast. Echter, het voorspellen van informatie is zeer handig om bijvoorbeeld het weer te voorspellen.Het voorspellen van informatie
Aan de hand van ontvangen informatie kan een patroon worden ontdekt door een algoritme. Aan de hand van dit patroon kan het volgende stukje informatie worden voorspeld. Een simpel algoritme om dit patroon te vinden, is lineaire regressie. Het idee van lineaire regressie is om een wiskundig model te vinden. Dit wiskundige model wordt getest op de geobserveerde data. Het doel is om het verschil tussen het voorspelde datapunt en geobserveerde datapunt te minimaliseren. Het doel is om het verschil tussen het geobserveerde datapunt en voorspelde datapunt weg te werken, waardoor het model elk datapunt precies voorspelt, zoals geobserveerd. Aan dit model worden straffen toegekend. Dit zorgt ervoor dat het algoritme niet precies elk datapunt voorspelt, maar ook ongeziene data kan voorspellen.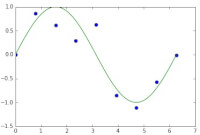 Figuur 1
Figuur 1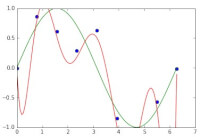 Figuur 2
Figuur 2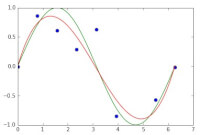 Figuur 3
Figuur 3Een voorbeeld
Neem een sinusoïde. Dit is de echte functie. Echter, wanneer dit signaal wordt gezien in de praktijk is er altijd sprake van ruis. Hierdoor ligt niet elk datapunt precies op de sinus, maar er omheen. In figuur 1 zijn de blauwe datapunten de geobserveerde data. De groene lijn is de daadwerkelijke functie die we willen voorspellen.
Zoals eerder genoemd, is het doel nu om een functie te bedenken die elk datapunt correct voorspelt. Echter, later zorgen we er juist voor dat het algoritme fouten gaat maken. In figuur 2 wordt de data precies voorspeld, weergegeven door de rode lijn.
Hoewel het rode lijntje nu specifiek weergeeft elk datapunt voorspelt, komt het geleerde model niet overeen met de sinus. Dit betekent dat de gewenste functie dus niet wordt voorspeld. Door strafpunten in te voeren, zal het geleerde model niet elk datapunt precies voorspellen, maar het onderliggende model. Dit wordt weergegeven in figuur 3.
Zoals kan worden gezien, wordt het onderliggende model zo goed mogelijk benaderd. Het zou ideaal zijn om deze precies te benaderen, maar in de werkelijkheid is dit vaak niet mogelijk.
Perfecte voorspelling
Zoals eerder genoemd leert het model eerst om alle data precies te voorspellen. Hierna worden het model "gestraft", omdat het te goed werkt. Dit gebeurt, doordat van tevoren vaak niet duidelijk is hoe de data eruit ziet. Als alleen datapunten worden ontvangen, zonder het onderliggende model, moet het model alsnog worden benaderd. Doordat deze informatie allemaal onbekend is, wordt worden alle geobserveerde datapunten eerst perfect geleerd, waarna het model wordt aangepast om ook ongeobserveerde data zo goed mogelijk te voorspellen. Om te bepalen wanneer de geobserveerde data perfect wordt voorspeld, wordt vaak de least squares approach gebruikt. Dit betekent dat het verschil tussen de voorspelling en het geobserveerde datapunt wordt berekend en gekwadrateerd. Dit getal moet uiteindelijk zo klein mogelijk worden.Strafpunten
Het geleerde model krijg strafpunten toegekend nadat het perfect elk geobserveerde datapunt voorspelt. Echter, deze datapunten worden gebruikt om een model te leren dat ook ongeobserveerde data zo goed mogelijk moet voorspellen. Door expres een error te introduceren, kan het geleerde model breder worden toegepast dan alleen op de geobserveerde data.© 2015 - 2025 Ai-nator, het auteursrecht van dit artikel ligt bij de infoteur. Zonder toestemming is vermenigvuldiging verboden. Per 2021 gaat InfoNu verder als archief, artikelen worden nog maar beperkt geactualiseerd.
 De lineaire hypotheek, voor- en nadelenDe lineaire hypotheek is een hypothecaire lening waarmee de aankoop van bijvoorbeeld een huis gefinancierd kan worden. G…
De lineaire hypotheek, voor- en nadelenDe lineaire hypotheek is een hypothecaire lening waarmee de aankoop van bijvoorbeeld een huis gefinancierd kan worden. G…
 Geschiedenis van de wiskunde: Babylonische WiskundeDe Babyloniërs rekenden met eenheden van 60. Ze gebruikten het zestigtallig of sexagesimaal stelsel. Dit lijkt heel onge…
Geschiedenis van de wiskunde: Babylonische WiskundeDe Babyloniërs rekenden met eenheden van 60. Ze gebruikten het zestigtallig of sexagesimaal stelsel. Dit lijkt heel onge…
 Het fenomeen tijdVan tijd tot tijd kunnen we weer vaststellen dat tijd maar een relatief begrip is. Terwijl we in Europa in de file staan…
Het fenomeen tijdVan tijd tot tijd kunnen we weer vaststellen dat tijd maar een relatief begrip is. Terwijl we in Europa in de file staan…
Gerelateerde artikelen
Kunstmatige intelligentie: een inleidingEr wordt veel over gesproken: kunstmatige intelligentie. Volgens velen is dit het einde van de mensheid. Robots zullen i…
recensieBoek: Children's past lives - Carol BowmanEr zijn al veel boeken geschreven over regressie. Toch is er maar één dat het onderwerp kinderen en regressie zo uitgebr…
Organisatieleren: de actietheoretische benaderingDe actietheoretische benadering is één van de benaderingen waaruit gekeken kan worden naar het leren van organisaties. D…
Bronnen en referenties
- Christopher M. Bishop: Machine learning and pattern recognition
- http://en.wikipedia.org/wiki/Linear_regression
- http://en.wikipedia.org/wiki/Least_squares
Ai-nator (2 artikelen)
Gepubliceerd: 02-03-2015
Rubriek: Wetenschap
Subrubriek: Wiskunde
Bronnen en referenties: 3
Gepubliceerd: 02-03-2015
Rubriek: Wetenschap
Subrubriek: Wiskunde
Bronnen en referenties: 3
Per 2021 gaat InfoNu verder als archief. Het grote aanbod van artikelen blijft beschikbaar maar er worden geen nieuwe artikelen meer gepubliceerd en nog maar beperkt geactualiseerd, daardoor kunnen artikelen op bepaalde punten verouderd zijn. Reacties plaatsen bij artikelen is niet meer mogelijk.