Vier vormen van validiteit in onderzoek
Wetenschappelijk onderzoek is bedoeld om iets te weten te komen, om kennis te vergaren, wetmatigheden aan te tonen. De belangrijkste eis: valide conclusies. Dat wil zeggen: het design van de studie moet van dien aard zijn dat alternatieve verklaringen voor de resultaten zo veel mogelijk uitgesloten worden. Er kunnen vier vormen van validiteit onderscheiden worden.Vier vormen van validiteit
- Interne validiteit: is een verschil tussen groepen inderdaad toe te schrijven aan de experimenteel interventie/manipulatie, en niet aan een invloed van buiten af?
- Externe validiteit: is welke mate kunnen de resultaten gegeneraliseerd worden naar andere personen, situaties, condities, metingen en tijdstippen dan die deel uitmaakten van de specifieke onderzoeksopzet.
- Constructvaliditeit: is een geconstateerd verschil inderdaad toe te schrijven aan de werkzaam geachte factor van de interventie? Het gaat hier dus om de verklarende factor.
- Statistische conclusievaliditeit: is de studie in statistische opzicht zodanig opgezet dat een kwantitatieve conclusie mogelijk is? Het gaat om vragen als: kan het onderzoek een echt verband ook detecteren, en wat stelt een aangetoond verband voor? Factoren die hierbij een rol spelen zijn de keuze van α, β (of Power (=1-β)), de steekproefgrootte (N) en tot slot de te verwachten Effect Size.
Bovenstaande vormen van validiteit zijn van toepassing op zowel experimenteel onderzoek als andere vormen van onderzoek zoals correlationeel onderzoek. Wat betreft de vier vormen van validiteit moet de onderzoeker eigen prioriteiten stellen. Vaak stelt men de interne validiteit zeker, om later een betere externe validiteit te krijgen. Streven naar een goede constructvaliditeit is pas mogelijk als de interne validiteit gewaarborgd is. Maatregelen ter bevordering van de statistische validiteit vereisen enig wiskundig inzicht. Construct validiteit wordt soms in twee verschillende vormen gebruikt: voor een onderzoek en voor een meetinstrument.
Interne validiteit
Deze kan bedreigd worden door verschillende factoren van buitenaf die tijdens het onderzoek hun invloed doen gelden:- Geschiedenis (history): hier gaat het om alle tussentijdse gebeurtenissen binnen of buiten de onderzoekssituatie, ánders dan de onafhankelijke variabele(n), die invloed op de resultaten kunnen uitoefenen. Voorbeelden: geluid van drilboor tijdens een experiment, extreem weer, politieke omslag.
- Rijping (maturation): nu gaat het om innerlijke processen die zich binnen de proefpersonen afspelen en die een onbedoeld effect op de resultaten kunnen hebben. Voorbeelden: innerlijke groei, toenemende vermoeidheid tijdens experiment.
- Herhaald testen (testing): het getest worden op de voormeting kan invloed hebben op de tweede keer testen (de nameting; eventueel verdere follow-up metingen). Zo kan herinnering aan wat men de eerste keer invulde van invloed zijn op de volgende meting, samen met de neiging juist wel of juist niet verschillend te willen scoren. Gaat het om prestatiegerichte tests, dan kan van de eerdere testafname een leereffect zijn uitgegaan.
- Instrumentatie: als men metingen vergelijkt, moet wel zeker zijn gesteld dat het meetinstrument zelf ondertussen niet veranderd is. (Vooral bij langlopende studies)
- Statistische regressie: als je op de voormeting groepen selecteert met extreme scores (bijv. een groep extreem hoog angstige personen en een groep extreem laag angstige), is er op de nameting bij beide groepen om statistische redenen een tendens om meer naar het gemiddelde toe te scoren, los van het effect van een eventuele interventie. Het effect van de interventie kan hierdoor versluierd raken.
- Bias bij proefpersoon selectie: het gaat hier om systematische verschillen tussen groepen aan het begin van het onderzoek, anders dan een bedoeld verschil, zodat de groepen in deze opzichten niet equivalent (gelijkwaardig) zijn. De oplossing: aselecte (random) toewijzing bij een voldoende grote steekproef.
- Uitval van proefpersonen (attrition): uitval maakt dat aanvankelijk equivalente groepen in de loop van het onderzoek hun equivalentie verliezen. Dit is ook het geval als in de groepen evenveel personen zijn uitgevallen, want de uitval kan toch verschillende kenmerken betreffen. Uitval speelt ook negatief in op andere vormen van validiteit.
- Combinaties: bovenstaande bedreigingen kunnen ook gelden voor slechts één groep, zodat er dus een combinatie ontstaat van selectie en een andere dreiging.
- Diffusie van de behandeling tussen groepen: Soms krijgt de controlegroep, min of meer per ongeluk, toch een vorm van behandeling. De groepen hebben hierdoor een minder verschillende behandeling gekregen dan de bedoeling was.
- Reactiviteit van de controlegroep: personen uit de controlegroep kunnen, als zij merken in de controleconditie te zitten, hierop reageren door er de pest in te hebben en slechter te scoren, of uit competitieoverwegingen juist een extra gunstige voorstelling van zaken geven, kortom: reactief te scoren.
Externe validiteit
De mate waarin de resultaten gegeneraliseerd kunnen worden naar andere personen, situaties, condities, metingen en tijdstippen dan die deel uitmaakten van de specifieke onderzoeksopzet. De volgende factoren vormen een bedreiging van de externe validiteit:- Eigenschappen van de steekproef: belangrijke variabelen hier zijn vooral sekse, leegtijd en opleidingsniveau. Voorbeeld: resultaten verkregen bij onderzoek van mannen tussen de 20 en 40 jaar, kunnen niet zomaar gegeneraliseerd worden naar vrouwen of naar personen van alle leeftijden. Er zijn ook onzekerheden van de generalisatie van onderzoek van dieren naar de mens (bijv. geneesmiddelen). Verder wordt veel onderzoek gedaan met psychologiestudenten: in hoeverre zijn de resultaten naar andere bevolkingsgroepen te generaliseren.
- Stimuluseigenschappen en setting: resultaten blijken vaak settinggebonden. Voorbeeld: de ene angstwekkende stimulus geeft een ander effect dan een andere. Effecten van psychotherapie blijken vaak gunstiger in het laboratorium dan in een praktijksetting.
- Reactiviteit van de proefpersoon: Het feit dat iemand zich bewust is deel te nemen aan een onderzoek heeft op zich al vaak een effect op de resultaten, los van de aangeboden conditie. NB: het feit dat proefpersonen zich ervan bewust zijn een interventie te krijgen, vormt geen bedreiging van de externe validiteit, want in de praktijk waarnaar men wil generaliseren, is men zich eveneens bewust van de interventie.
- Interferentie van verschillende interventies na elkaar: in sommige designs doorlopen de proefpersonen meer dan één interventie. Bijvoorbeeld: eerst wordt interventie 1 gegeven zonder effect. Daarna interventie 2 met effect. Dan kan dit effect niet alleen worden toegeschreven aan alleen de tweede interventie: het enige dat is vastgesteld is dat deze tweede interventie effect sorteert als deze ná de eerste wordt gegeven.
- Reactiviteit van de meting: proefpersonen zijn zich er tijdens een onderzoek van bewust dat hun gedrag geregistreerd wordt en veelal hebben zij ook een idee om welk aspect het gaat. Dit leidt tot iets ander gedrag dan zij in het dagelijkse leven vertoond zouden hebben en vormt daardoor dus een bedreiging voor de externe validiteit. Een enkele keer lukt het om met unobstrusive measures te werken. De proefpersoon weet dan niet wat er geobserveerd of gemeten wordt. Soms verzetten ethische beginselen hiertegen.
- Test sensitisatie: het gaat hier niet om het effect van de voormeting op de nameting, maar om een mogelijk effect van de voormeting op de interventie zelf. Door de voormeting kunnen mensen gesensitiseerd raken voor de interventie en deze daardoor anders beleven: de interventie heeft dan een ander effect dan zonder de voormeting het geval zou zijn geweest. Voorbeeld: het invullen van een lijst zet iemand al aan het denken, en zodoende zal deze de interventie anders ingaan. Hierdoor zijn de resultaten niet generaliseerbaar naar mensen die geen voormeting hebben gehad. Maar het hoeft niet altijd een bedreiging te zijn: als in de praktijk waarnaar gegeneraliseerd wordt ook eerst een voormeting wordt afgenomen, dan vormt de voormeting als het ware een deel van de behandeling een vormt deze geen bedreiging voor de externe validiteit.
- Timing van de metingen: in het meest voorkomende geval meet men direct na een interventie of er een effect is. De vraag is of het stand houdt. Meerdere follow-up metingen zijn nodig. Het kan ook zo zijn dat direct na een meting geen effect is, maar een paar weken later wel.
Constructvaliditeit
Als eenmaal een relatie is aangetoond tussen bepaalde interventie, manipulatie en een uitkomstvariabele, dan is de vraag: welk aspect van de interventie is verantwoordelijk voor dit effect? Het gaat hier om het verklarende mechanisme. Een aantal voor de hand liggende verklaringen die uitgesloten kunnen worden:- Aandacht en contact met de proefpersoon: De interventie betekent bijna altijd ook: aandacht voor en contact met de proefpersoon. Dit alleen al zou de of een werkzame factor kunnen zijn: een eventueel verschil tussen de interventie en de non-interventie groep zou dan hieraan kunnen worden toegeschreven. ‘Aandacht’ of ‘contact’ vormen dus een bedreiging voor de construct validiteit. Men zou hier voor moeten controleren. Voorbeeld: door een controlegroep toe te voegen die wel aandacht/contact krijgt, maar niet de werkzaam geachte factor van de interventie.
- De interventie bestaat uit een te beperkte stimulus of ingreep: men ziet dit nogal eens bij therapie onderzoek wanneer de werkzaamheid van twee interventies (A en B) met elkaar wordt vergeleken.
- M.b.t. de ingreep: Stel therapeut I voert interventie A uit en therapeut II voert interventie B uit. Als er nu verschillen worden gevonden, zijn deze dan toe te schrijven aan het verschil in interventie of aan het verschil in therapeut? Als oplossing zou je 1 therapeut beide interventies kunnen laten doen. Maar misschien is deze therapeut wel meer bedreven of meer enthousiast voor een van beide interventies. Een betere oplossing: meerder therapeuten voeren beide interventies uit en dan moet met toetsen of er sprake is van een interventie effect, een therapeut effect en/of een interactie effect (therapeut x interventie).
- M.b.t. de stimulus: bijvoorbeeld als de proefpersoon iets moet beoordelen dat wel erg op toevalligheden berust, zoals één filmpje. Het is belangrijk dan meerdere stimuli te gebruiken.
- Verwachtingen van de proefleider: het is allereerst belangrijk onderscheid te maken tussen de onderzoeker (investigator) en de proefleider (experimentator). Eén persoon kan beide rollen hebben. Het gaat hier om de rol van de proefleider: aangetoond is dat de verwachtingen van de proefleider een zelfbevestigend effect op de resultaten hebben. Zo is vaak gebleken dat de favoriete therapievorm van de proefleider in door hem of haar uitgevoerd onderzoek het beste werkt. Oplossing: de proefleider ‘blind’ maken voor de soort conditie.
- Cues (demand characteristics) van de onderzoekssituatie: proefpersonen vormen zich vooraf al een beeld van het onderzoek, onder andere op basis van de informatie die er over het onderzoek circuleert. Hierdoor gaan zij de interventie op een bepaalde manier interpreteren en dit heeft een onbedoeld effect op de construct validiteit.
Hiernaast heeft ieder onderzoek zijn eigen construct-specifieke bedreigingen.
Statistische conclusie validiteit
Deze vorm van validiteit wordt vaak over het hoofd gezien. Het gaat hier om de kwantitatieve aspecten van de studie die de mogelijkheden om een juiste conclusie te trekken beïnvloeden. Parameters die hier een rol in spelen zijn: alpha (α), beta (β) of Power (=1-β), de steekproefgrootte (N) en de Effect size (ES of d). Deze parameters zijn onderling gerelateerd. Meestal kiest men voor een bepaalde Power en α en tracht men van te voren een Effect size te schatten, om dan uit te rekenen of in een tabel op te zoeken welke steekproefgrootte N nodig is om in het onderzoek valide conclusies te kunnen trekken.De alpha (α)
Een verschil tussen twee of meer groepen kan alleen worden aangetoond door de nulhypothese, die stelt dat er géén verschil tussen de groepen is, door middel van een statistische toets te verwerpen. Dit verwerpen geschiedt altijd met een foutenmarge (α). Dit is dan de kans om de nulhypothese te verwerpen (en daarmee te concluderen dat de groepen wél verschillen, terwijl in feite de nulhypothese juist is. Dit betekent dat in werkelijkheid in de populatie waarnaar je wilt generaliseren de groepen niet verschillen. Dit wordt ook wel een type I fout of een fout van de eerste soort genoemd. Men concludeert tot verbanden die er niet zijn, daarom wordt ook wel van overtheoretisering gesproken.
Meestal wordt de alpha vooraf gesteld op α=0.05. Dit betekent letterlijk: als het onderzoek 100 keer uitgevoerd zou worden, zou men vijf keer ten onrechte concluderen dat dat er in werkelijkheid een verschil tussen beide groepen bestaat.
Een statistische toets (bijvoorbeeld een t-toets) wordt ingezet om vast te stellen hoe groot in een bepaald onderzoek de type I fout feitelijk is, gegeven de scores van de proefpersonen uit beide groepen. Deze feitelijk gevonden waarde wordt niet aangeduid als α, maar als overschrijdingskans p.
- Wanneer p ≤ α : het resultaat is significant, er is een significant verschil tussen beide groepen. De nulhypothese moet verworpen worden.
- Wanneer p > α : het resultaat is niet significant, er is geen significant verschil tussen beide groepen. De nulhypothese moet geaccepteerd worden.
Wanneer men van te voren een richting van een mogelijk verschil had voorspelt (bijvoorbeeld groep 1 is groter of gelijk aan groep 2) dan mag de gevonden p-waarde door twee worden gedeeld (éénzijdige-toetsing genoemd).
Statistische significantie is een directe functie van groepsgrootte: hoe groter de groepen, des te kleiner het verschil dat nodig is om bij een bepaalde foutmarge (α) significantie te bereiken.
β of Power
Tegenover een fout van de eerste soort staat de kans dat de nulhypothese wordt aanvaard (dat er geen verschil is tussen twee groepen), waarbij in de werkelijkheid (in de populatie waarnaar men wil generaliseren), wél een verschil bestaat. Dit wordt ook wel ondertheoretisering genoemd. Deze kans wordt β genoemd: de kans om de nulhypothese te aanvaarden terwijl deze onjuist is (een fout van de tweede soort/type II fout). Vaak wordt β = 0,20 gebruikt. Gaat het echter om onderzoek waarbij men een mogelijk effect beslist niet wil missen, dan kan men een kleinere β kiezen (bijv. naar onderzoek of een bepaalde ingreep schade aan de proefpersoon teweegbrengt). De type II fout drukt men vaak uit in het begrip ‘Power’. De Power is 1 minus de β. De kans om de nulhypothese te verwerpen terwijl deze inderdaad onjuist is (je doet het dus goed). Je haalt hierbij β (de kans de nulhypothese te accepteren terwijl deze onjuist is) van het getal 1 af. De 1 staat voor de totale kans. Je hebt 2 opties/kansen: het juiste doen (verwerpen) en het onjuiste doen (accepteren) van een onjuiste nulhypothese. Deze kansen bij elkaar opgeteld is altijd 1. De power is dus de kans om werkelijk bestaande verschillen te detecteren. Een power van 0.80 (want je doet 1-β, dus 1 - 0.20 = 0.80) betekent dat de onderzoeker een kans van vier uit vijf heeft om een in de populatie echt bestaand verschil te detecteren.
Men wil de α zo klein mogelijk houden en de Power zo groot mogelijk.
Tabel: Overzicht van de mogelijke combinaties.
| [/TH][TH]Werkelijkheid: geen groepsverschil | Werkelijkheid: wel een groepsverschil | |
|---|---|---|
| Onderzoeksconlcusie: de groepen verschillen | Type I fout (α): verwerpen van een juiste nulhypothese (overtheoretisering) | Goede conclusie (Power: 1-β): nulhypothese verwerpen die onjuist is |
| Onderzoeksconlclusie: de groepen verschillen niet. | Goede conclusie: nulhypothese aanvaarden die juist is. | Type II fout (β): aanvaarden van een onjuiste nulhypothese. (ondertheoretisering) |
Effect grootte (Effect size, ES of d)
De grootte van de effect size komt neer op het verschil in gemiddelden m tussen twee groepen gedeeld door de (pooled) standaardafwijking van beide groepen: ES = (m1-m2) / s
De standaardafwijking s is een maat voor de variabiliteit rond het gemiddelde, namelijk de wortel uit de variantie:
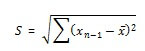
Verder geldt dat, als de standaardafwijkingen van beide groepen verschillen (s1 en s2), men beide afzonderlijke standaardafwijkingen combineert. Men houdt hierbij rekening met de grootte van de groepen (N) en zo krijgt men de pooled standaardafwijking (s).
Hoe groter het verschil in de groepsgemiddelden (m1-m2), des te groter de Effect size. Hoe kleiner de standaardafwijkingen (dus een kleiner noemer), des te groter de Effect size en des te meer onderscheiden beide groepen zich van elkaar. Er is dan een grotere kans op een significant verschil. Zie afbeelding blz. 40.
Voor schattingen van de Effect size baseert men zich onder andere op resultaten van meta-analyses van verwante studies.
Benodigde steekproefgrootte (N)
De α, β/power, effect size en steekproefgrootte zijn onderling gerelateerd, in die zin dat al er drie vaststaan, de vierde ook vaststaat. Meestal wordt benodigde N berekent aan de hand van de overige drie. Hier kan men overzichtstabellen voor raadplegen.
Bedreiging van de statistische conclusie validiteit
Een aantal bedreigingen voor de statistische conclusie validiteit van een onderzoek:[OLIST]Geringe statistische Power: Hoe groter een van de parameters (α, β of de Effect size) des te groter de Power.
Grote standaardafwijking (s) in de uitkomstmaat (de noemer in de formule voor de Effect size). Deze kan onnodig groot zijn door:[/OLIST]
- Variabiliteit in de onderzoeksprocedures.
- Heterogeniteit van proefpersonen.
- Onbetrouwbaarheid van de metingen (geeft een random variatie)
- Gebruik van vele toetsen tegelijk: Bij één toets is de type I fout gelijk aan α. Toetst men het verschil tussen twee groepen op meerdere variabelen, dan zijn ook meerdere toetsen nodig. Bij meerdere toetsen met dezelfde proefpersonen, moet je, om dezelfde, tevoren afgesproken Type I fout e houden en niet te gaan overtheoretiseren, de α evenredig verkleinen. Dit kan onder Andre met de Bonferroni correctie, de Tukey-correctiue of de Scheffe-correctie.
Maatregelen om de Power te verhogen
- Vergroot de steekproef (N)
- Versterk de experimentele manipulatie: vergroot het contrast tussen beide groepen, daarmee neemt de Effect size toe.
- Gebruik een voormeting zodat (ook) een within groups analyse mogelijk is (er worden dan steeds twee metingen per persoon vergeleken).
De formule voor de effect size voor een between groups analyse:
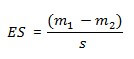
De formule voor de effect size voor een within groups analyse:
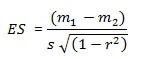
Hierbij geldt: (1-r^2 )<1, want r is altijd een getal tussen -1 en 1 in en r^2 wordt dus tussen 0 en 1.
Hierdoor is de noemer kleiner en dus de ES groter.
Er zijn ook designs die zowel een within groups als between groups analyse mogelijk maken.
- Neem α eenzijdig als de hypothese een richting voorspelt. (verdubbeling van de α)
- Verminder de variabiliteit (de error) in de studie: homogene groepen, precieze manipulaties, storende factoren in de hand houden, gebruik van betrouwbare meetinstrumenten.