T-toets 3 - gemiddelden afhankelijke steekproeven
Een t-toets derde variant wordt uitgevoerd om te kijken of een verschil tussen twee afhankelijke steekproeven significant verschillen. Oftewel: is er meer aan de hand dan toeval? Er kan bijvoorbeeld gekeken worden of een voormeting significant verschilt van een nameting. Wat wordt er bedoeld met ‘afhankelijke steekproeven’ en hoe bereken je of de gemiddelden significant verschillen?T-toets derde variant: Gemiddelden van afhankelijke steekproeven vergelijken
Met afhankelijke steekproeven wordt bedoeld dat de waarden die gemeten worden elke keer bij dezelfde persoon horen. Dit is bijvoorbeeld het geval bij een voor- en nameting zoals vaak bij trainingen gedaan worden. Een vraag kan bijvoorbeeld zijn: hoeveel weegt u? Vervolgens wordt een dieet gevolgd, waarna dezelfde vraag nogmaals gesteld wordt aan dezelfde persoon. Zo ontstaan paren van gegevens. Daarom wordt deze toets ook wel t-toets voor gepaarde gegevens genoemd. Hieruit vloeit voort dat de steekproeven altijd hetzelfde aantal onderzoeksobjecten heeft. Bij een t-toets tweede variant kunnen de steekproeven even groot zijn, maar dat hoeft niet.Vervolgens wordt gekeken of het verschil tussen de steekproeven dan ook significant is. Dus: ‘Heeft het dieet invloed op het gewicht?’ (tweezijdige toetsing) of ‘Zorgt het dieet voor een daling in gewicht?’ (eenzijdige toetsing).
De formule
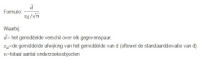
Voor het berekenen van het gemiddelde verschil over elk gegevenspaar:
Stap 1: Kijk naar je hypothese welke gegevens je van welke aftrekt (bij tweezijdige toetsing maakt dat niet uit)
Stap 2: Trek één voor één de paren van elkaar af
Stap 3: Tel alle uitkomsten op
Stap 4: Deel dit door het aantal metingen (n)
Vrijheidsgraden
Het aantal vrijheidsgraden wordt bij de T-toets eerste variant bepaald door het aantal meetwaarden min 1. Dit komt in formulevorm neer op:Df = n-1
Df staat voor degrees of freedom.
Voorbeeld
Een onderzoeker wil weten of studenten op toets B beter zullen scoren dan op toets A. Daarvoor neem hij bij 15 studenten de toets af. De toetsen komen qua inhoud overeen en voor de toets kunnen maximaal 100 punten gehaald worden. De standdeviatie is 8,9 punten. Hij wil dit testen met een alfa van 1%.| Student | Cijfer toets A | Cijfer toets B | Verschil |
|---|---|---|---|
| 1 | 100 | 95 | [/TD] |
| 45 | 65 | [/TD] | |
| 61 | 65 | [/TD] | |
| 88 | 75 | [/TD] | |
| 91 | 92 | [/TD] | |
| 32 | 45 | [/TD] | |
| 44 | 56 | [/TD] | |
| 63 | 67 | [/TD] | |
| 89 | 84 | [/TD] | |
| 64 | 63 | [/TD] | |
| 76 | 74 | [/TD] | |
| 75 | 71 | [/TD] | |
| 78 | 82 | [/TD] | |
| 69 | 79 | [/TD] | |
| 81 | 85 | [/TD] |
Alternatieve hypothese: De studenten scoren beter op toets B dan op toets A
Bereken vervolgens B-A per gegevenspaar (zie tabel).
| Student | Cijfer toets A | Cijfer toets B | Verschil (B-A) |
|---|---|---|---|
| 100 | 95 | -5 | |
| 2 | 45 | 65 | 20 |
| 3 | 61 | 65 | 4 |
| 4 | 88 | 75 | -13 |
| 5 | 91 | 92 | 1 |
| 6 | 32 | 45 | 13 |
| 7 | 44 | 56 | 12 |
| 8 | 63 | 67 | 4 |
| 9 | 89 | 84 | -5 |
| 10 | 64 | 63 | -1 |
| 11 | 76 | 74 | -2 |
| 12 | 75 | 71 | -4 |
| 13 | 78 | 82 | 4 |
| 14 | 69 | 79 | 10 |
| 15 | 81 | 85 | 4 |
| Gemiddelde | 1056/15=70,4 | 1098/15=73,2 | 42/15=2,8 |

De gevonden t-waarde is 1,2185. De kritieke waarde bij df van 14 en een alfa van 1% is 2,624. Dit betekent dat de studenten niet significant beter scoren op toets B. Daardoor blijft de nulhypothese staan en wordt de alternatieve hypothese verworpen.